Window関数
Window関数とは
Window関数は、データベースクエリやデータ処理のコンテキストで使用される関数の一種です。
主に集計(Aggregation)操作において、特定のデータセットの一部(ウィンドウ)に対して演算を行うために使用されます。
行ごとに個別の計算を行うためのデータセットを指定する方法を提供し、その結果を元のクエリ結果に結合することができます。
また、Window関数は、集計関数(例: SUM、AVG、ROW_NUMBER)と組み合わせて使用され、データセット内の行に対して特定の条件や順序で計算を実行するのに役立ちます。 一般的な用途として、ランキング、累積合計、平均値の計算などが挙げられます。
Window関数の構文と動作は、使用するデータベースシステムやクエリ言語によって異なることがありますが、基本的なアイデアはデータセット内の行に対する柔軟な演算を可能にすることです。
今回はMySQLを例に説明していきます
MySQLはVer8.0からWindow関数を利用できます
Window関数の基本
Window関数は、必ず OVER キーワードと一緒に使います。
そして、関数と名が付く通り、実行した結果1つの値が返されます。
つまり、select 文で返される1行1行について、Window関数が実行されます。
従って、 Window関数は、select文の中に記述します。
select
column1,
column2,
sum(column1) over(partition by column1 order by column2) // Window関数
from hoge
OVER
全てのWindow関数にはOVER句が必要となります。いわば、OVER句はWindow関数を使いますというサインです。
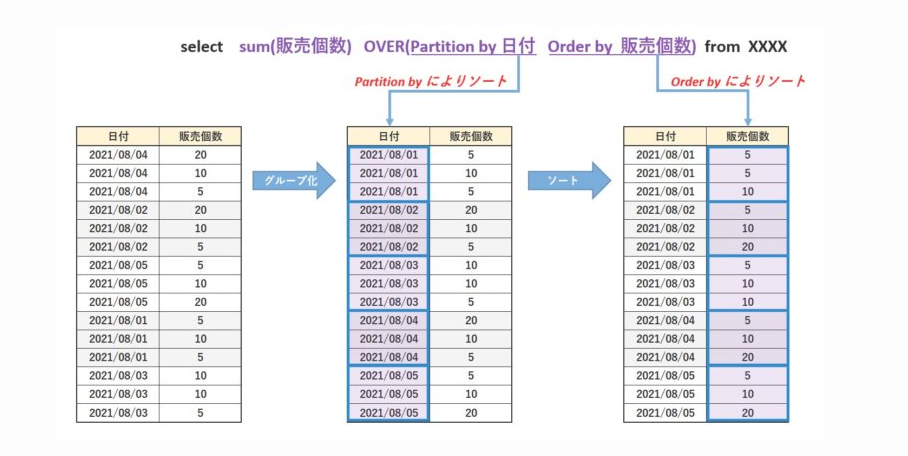
このOVER() のカッコの中に、Partition by や Order by を指定することで、グルーピング(=パーティション)した中身をソートし、それぞれに対してWindow関数が実行されるのです。
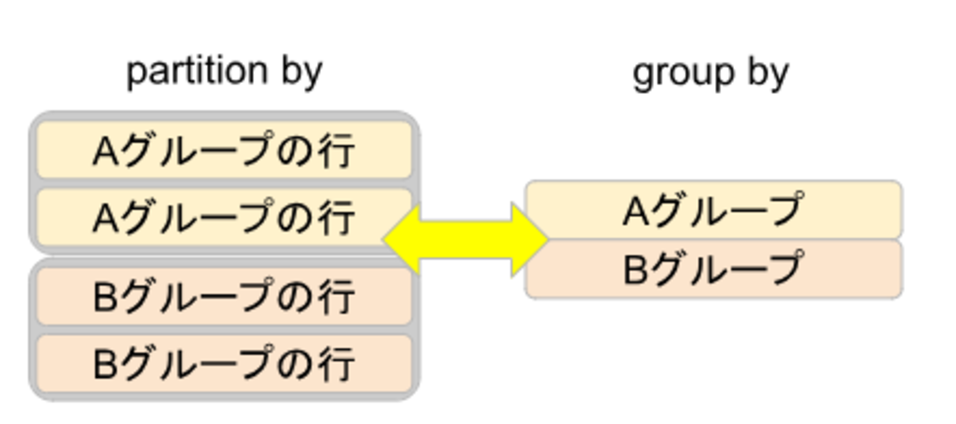
Partition by によるグルーピング
OVER の中に Partition by を書くことで、指定した項目でグループ化することが可能です。
Window関数() OVER(Partition by カラム1,カラム2,・・・)
これは、SQL の Group by 句 でグルーピングするのと同じ動作になります。
Order by によるソート
OVER の中に Order by を書くことで、指定した項目でソートすることが可能です。
Window関数() OVER(Order by カラム1,カラム2,・・・)
これも SQL の Order by 句でソートするのと同じ動作になります。
Group ByとOrder by の効くタイミングの違い
Group by 句はグループ毎に集計を行うもので、その結果に対して Order by 句によりソートが行われます。
それに対してWindow関数の Partition by と Order by は、グループ毎にグループの中身をソートするという違いがあります。
集計結果の現れ方の違い
先ほどの説明と重複しますが、Group By 句 やグルーピングして出来上がったグループに対して、それぞれに集計結果が計算され、その結果が Order by 句 でソートされます。
一方、OVER() では、 Partition by で グルーピングされ、さらにその中で Order by によってソートされ、その集計結果がそれぞれの行に付加されます。
参照) 【ひたすら図で説明】一番やさしい SQL window 関数(分析関数) の使い方
partition byとgroup byとの違いは詳しくはこちら
Window関数一覧
| 関数名 | 内容 |
|---|---|
| ROW_NUMBER() | 行の順序に基づいて各行に一意の番号を割り当てます。これはランキングや行の順序付けに使用されます |
| RANK() / DENSE_RANK() | データ内の行を順位付けるために使用されます。RANK()は同じ順位の行がある場合でも同じ順位を割り当て、DENSE_RANK()は同じ順位の行に異なる順位を割り当てます |
| SUM() OVER() | ウィンドウ内の行の合計を計算します。これにより、累積合計を求めたり、特定のウィンドウ内の合計を計算したりすることができます |
| AVG() OVER() | ウィンドウ内の行の平均値を計算します。データの平均値をウィンドウ内で計算することができます |
| LEAD() / LAG() | LEAD()は指定された行の前または後の行の値を取得し、LAG()は指定された行の前または後の行の値を取得します。これを使用して前後の行との比較を行ったり、トレンドを分析したりすることができます |
| FIRST_VALUE() / LAST_VALUE() | グループ内の最初や最後の行の値を取得します。これは、グループ内での最初や最後のイベントなどを特定するのに役立ちます |
| PERCENT_RANK() | グループ内の行がどれだけのパーセンタイルに位置するかを示す相対的な順位を計算します |
| LISTAGG() | 文字列の連結を行い、グループ内の値を1つの文字列にまとめます。これは、カンマで区切られたリストやカテゴリごとのデータの結合に使用されます |
| CUME_DIST() | 現在の行がグループ内でどれだけの割合を占めているかを示す累積分布関数を計算します |
それでは、いくつか具体的にWindow関数はどのようにつかわれるか見ていきましょう。
ROW_NUMBER
従業員ごとに給与を記録しているテーブルがあるとしましょう。
その従業員テーブルから各部署ごとに給与が高い順に従業員をランク付けするクエリを考えてみましょう。
| EmployeeID | FirstName | LastName | DepartmentID | Salary |
|---|---|---|---|---|
| 1 | John | Doe | 101 | 60000.00 |
| 2 | Jane | Smith | 101 | 70000.00 |
| 3 | Bob | Johnson | 102 | 80000.00 |
| 4 | Alice | Williams | 102 | 75000.00 |
| 5 | Charlie | Brown | 102 | 90000.00 |
| 6 | Eva | Davis | 102 | 80000.00 |
↓
| EmployeeID | FirstName | LastName | DepartmentID | Salary | SalaryRank |
|---|---|---|---|---|---|
| 2 | Jane | Smith | 101 | 70000.00 | 1 |
| 1 | John | Doe | 101 | 60000.00 | 2 |
| 5 | Charlie | Brown | 102 | 90000.00 | 1 |
| 3 | Bob | Johnson | 102 | 80000.00 | 2 |
| 6 | Eva | Davis | 102 | 80000.00 | 3 |
| 4 | Alice | Williams | 102 | 75000.00 | 4 |
Window関数を利用�しない場合
JOINやサブクエリが必要になり、複雑になってしまいます。
SELECT
e.EmployeeID,
e.FirstName,
e.LastName,
e.DepartmentID,
e.Salary,
COUNT(DISTINCT e2.Salary) + 1 AS SalaryRank
FROM
Employees e
JOIN
Employees e2 ON e.DepartmentID = e2.DepartmentID AND e.Salary < e2.Salary
GROUP BY
e.EmployeeID, e.FirstName, e.LastName, e.DepartmentID, e.Salary
ORDER BY
e.DepartmentID, Salary DESC;
Window関数を利用する場合
実行結果は同じでも簡潔にクエリを書くことができますね。
SELECT
EmployeeID,
FirstName,
LastName,
DepartmentID,
Salary,
ROW_NUMBER() OVER (PARTITION BY DepartmentID ORDER BY Salary DESC) AS SalaryRank
FROM
Employees;
RANK
顧客ごとに販売金額を記録しているテーブルがあるとします。
顧客ごとに売上データのランクを付けるクエリを考えてみましょう。
| SaleID | CustomerID | SaleAmount |
|---|---|---|
| 1 | 101 | 500.00 |
| 2 | 102 | 700.00 |
| 3 | 101 | 800.00 |
| 4 | 102 | 900.00 |
| 5 | 102 | 900.00 |
| 6 | 102 | 950.00 |
↓
| SaleID | CustomerID | SaleAmount | SalesRank |
|---|---|---|---|
| 3 | 101 | 800.00 | 1 |
| 1 | 101 | 500.00 | 2 |
| 6 | 102 | 950.00 | 1 |
| 4 | 102 | 900.00 | 2 |
| 5 | 102 | 900.00 | 2 |
| 2 | 102 | 700.00 | 4 |
Window関数を利用する場合
ROW_NUMBER()同様に簡潔にクエリを書くことができますね。
SELECT
SaleID,
CustomerID,
SaleAmount,
RANK() OVER (PARTITION BY CustomerID ORDER BY SaleAmount DESC) AS SalesRank
FROM
Sales;
1.重複した値の処理
ROW_NUMBER()は同じ順位がある場合に値が異なるランキングを割り当てます。
つまり、同じ値が複数ある場合、それらの行のランキングは異なります。
RANK()は同じ値がある場合、同じランクが割り当てられ、その後のランクはスキップされます。
例えば、同じ最大値を持つ2つの行がある場合、それらには同じランクが割り当てられ、その後のランクはスキップされます。
2.パフォーマンス
ROW_NUMBER()は行ごとに一意のランクを計算するため、異なる行が同じ値を持っていても異なるランクを割り当てます。そのため、計算に時間がかかることがあります。 RANK()は同じ値に対して同じランクを割り当てるため、ROW_NUMBER()よりもパフォーマンスが向上することがあります。
SUM
1日ごとに売上データを記録しているテーブルがあるとしましょう。
そのテーブルから日毎の売上データで各日の累積売上を計算するときを例に見てみましょう。
| date | amount |
|---|---|
| 2023-01-01 | 100.50 |
| 2023-01-02 | 150.25 |
| 2023-01-03 | 200.75 |
| 2023-01-04 | 120.00 |
| 2023-01-05 | 180.30 |
↓
| date | amount | cumulative_sales |
|---|---|---|
| 2023-01-01 | 100.50 | 100.50 |
| 2023-01-02 | 150.25 | 250.75 |
| 2023-01-03 | 200.75 | 451.50 |
| 2023-01-04 | 120.00 | 571.50 |
| 2023-01-05 | 180.30 | 751.80 |
Window関数を利用しない場合
SELECT
date,
amount,
(SELECT SUM(amount) FROM sales s2 WHERE s2.date <= s1.date) AS cumulative_sales
FROM
sales s1;
- 実行計画(1000件で実施)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | s1 | ALL | 1000 | 100 | ||||||
| 2 | DEPENDENT SUBQUERY | s2 | ALL | 1000 | 33.33 | Using where |
Window関数を利用する場合
Window関数を使用すると、データベースエンジンは一度のパスでデータを処理し、その結果からWindow関数を適用できます。
これにより、効率的なアクセスパターンを選択し、データを一度だけスキャンすることができます。
一方で、サブクエリを使用する場合、各行ごとにサブクエリが実行され、データを再度読み取ることが必要です
実行計画をみれば一目瞭然ですね。
SELECT
date,
amount,
SUM(amount) OVER (ORDER BY date) AS cumulative_sales
FROM
sales;
- 実行計画(1000件で実施)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | sales | ALL | 1000 | 100 | Using filesort |
LEAD
この例では、attendance_recordsというテーブルがあり、従業員の出退勤情報が含まれていると仮定します。
出勤・退勤情報から次の出勤・退勤情報を取得するクエリを考えてみましょう。
このとき、従業員ごとに日付ごとに出勤・退勤情報を時刻の昇順でソートするという条件があるとします。
| employee_id | action_type | action_time |
|---|---|---|
| 2 | check_in | 2023-01-01 08:45:00 |
| 1 | check_in | 2023-01-01 09:00:00 |
| 2 | check_out | 2023-01-01 17:30:00 |
| 1 | check_out | 2023-01-01 18:00:00 |
| 2 | check_in | 2023-01-02 09:15:00 |
| 1 | check_in | 2023-01-02 09:30:00 |
| 2 | check_out | 2023-01-02 18:15:00 |
| 1 | check_out | 2023-01-02 18:30:00 |
↓
| employee_id | check_in_type | check_in_time | check_out_type | check_out_time |
|---|---|---|---|---|
| 1 | check_in | 2023-01-01 09:00:00 | check_out | 2023-01-01 18:00:00 |
| 1 | check_in | 2023-01-02 09:30:00 | check_out | 2023-01-02 18:30:00 |
| 2 | check_in | 2023-01-01 08:45:00 | check_out | 2023-01-01 17:30:00 |
| 2 | check_in | 2023-01-02 09:15:00 | check_out | 2023-01-02 18:15:00 |
Window関数を利用する場合
WITH CheckInOutPairs AS (
SELECT
employee_id,
action_type AS check_in_type,
action_time AS check_in_time,
LEAD(action_type) OVER (PARTITION BY employee_id, DATE(action_time) ORDER BY employee_id, DATE(action_time), action_time) AS check_out_type,
LEAD(action_time) OVER (PARTITION BY employee_id, DATE(action_time) ORDER BY employee_id, DATE(action_time), action_time) AS check_out_time
FROM
attendance_records
WHERE
action_type IN ('check_in', 'check_out')
)
SELECT
employee_id,
check_in_type,
check_in_time,
check_out_type,
check_out_time
FROM
CheckInOutPairs
WHERE
check_in_type = 'check_in'
ORDER BY
employee_id, check_in_time;
partitionby, orderby は複数のカラムを指定することができることが確認できましたね
また、タイムシフトや比較など、連続した行との比較が必要な場面ではLEAD()を利用しましょう
AVG
最後に移動平均を計算するための例を見てみましょう
移動平均とは、時系列データの傾向を平滑化するために使用される統計的手法の一つです。
この手法を時間に対して適用することで、データの変動を滑らかにし、トレンドを見やすくすることができます。
daily_salesテーブルがあり、日付 (date) と売上 (sales) のカラムがあると仮定します。
そのデータから過去3日間の売上の移動平均を計算する例を見てみましょう。
| date | sales |
|---|---|
| 2023-01-01 | 100.00 |
| 2023-01-02 | 150.00 |
| 2023-01-03 | 200.00 |
| 2023-01-04 | 120.00 |
| 2023-01-05 | 180.00 |
| 2023-01-06 | 130.00 |
| 2023-01-07 | 160.00 |
↓
| date | sales | moving_average |
|---|---|---|
| 2023-01-01 | 100.00 | 100.000000 |
| 2023-01-02 | 150.00 | 125.000000 |
| 2023-01-03 | 200.00 | 150.000000 |
| 2023-01-04 | 120.00 | 156.666667 |
| 2023-01-05 | 180.00 | 166.666667 |
| 2023-01-06 | 130.00 | 143.333333 |
| 2023-01-07 | 160.00 | 156.666667 |
Window関数を利用しない場合
SELECT
date,
sales,
(
SELECT AVG(sales)
FROM daily_sales AS sub
WHERE sub.date BETWEEN main.date - INTERVAL '2 days' AND main.date
) AS moving_average
FROM
daily_sales AS main;
Window関数を利用する場合
SELECT
date,
sales,
AVG(sales) OVER (ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_average
FROM
daily_sales;
PRECEDINGやCURRENTなど初めてみたキーワードが出てきましたね。これらはグループの範囲指定をするためのキーワードです。
| キーワード | 意味 |
|---|---|
| 「値」 PRECEDING | ROWSを指定した場合は、現在行より「値」行前。RANGEの場合はカラムの値が「値」の前 |
| 「値」 FOLLOWING | ROWSを指定した場合は、現在行の値が「値」行後。RANGEの場合はカラムの値が「値」の後 |
| UNBOUNDED PRECEDING | 先頭の行を指定する。終了点としては使えない |
| UNBOUNDED FOLLOWING | 末尾の行を指定する。開始点としては使えない |
| CURRENT ROW | 現在行(カーソル行) |
最後に
この記事を読んで、集計結果を取得したい場合などはWindow関数を使うという選択肢を持ってもらえれば幸いです!